
在我们编写好测试脚本后,通常是在IDE里面点击运行按钮运行我们的脚本,但是在IDE里面只能针对一个对象运行脚本,如何才能批量运行脚本呢。
在批量运行脚本里有两个需求,第一个是回归测试也就是一个手机运行多个脚本,另一个是兼容性测试也就是一个脚本在多个手机上运行。在IDE里运行脚本其实是经典的一对一场景,那么要实现批量运行脚本则需要脱离这种关系,实现一对多,多对一甚至是多对多。
1.安装Airtest
首先我们的Airtest脚本是基于ide环境运行的,那么要脱离ide第一步就是电脑环境要有Airtest,通过pip install airtest安装依赖,并通过pip list查看是否安装成功。
2.获取连接设备名称
因为要批量运行脚本,所以我们还应该知道连接设备的名称,不然执行的脚本和运行脚本的设备对应不上,可以通过airtest自带的adb工具查看已连接设备的名称,运用./adb devices查看连接设备名。

3.创建脚本
脚本创建时,首先了解单个脚本单设备执行
::关闭回显
@echo off
::切换到D盘
D:
::进入D盘的test目录
cd D:\Desktop
::执行 airtest run 命令
start airtest run testdemo.air
exit
其中,testdemo.air是所需执行脚本文件夹的名称,因为脚本不仅包含py文件,还有相应的截图。新建记事本,将上面代码复制后,修改脚本名称和执行目录名称,再将记事本的后缀.txt改为.bat即可完成脚本创建。脚本路径可以右键-属性进行查看
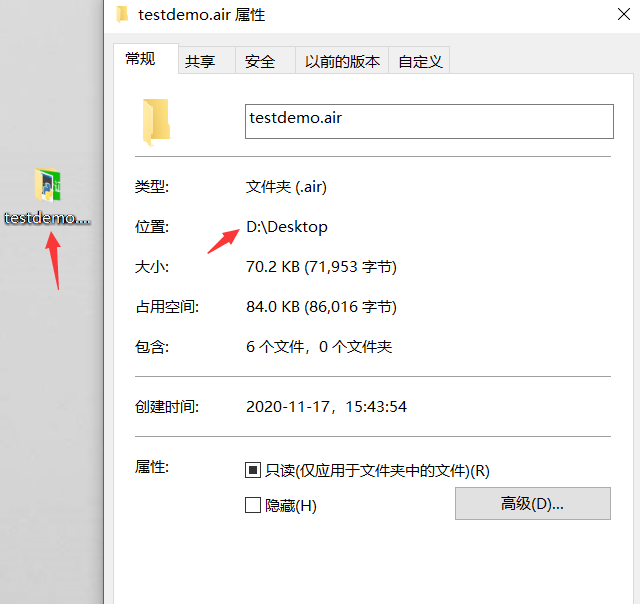
修改完成后双击bat文件即可执行脚本。其中airtest run关键字后可以带--device --log 和 --recording 等参数。
# 不带任何参数运行脚本
airtest run D:\Desktop\testdemo.air
# 带命令行参数运行脚本
airtest run D: \Desktop\testdemo.air --device Android:/// --log log/ --recording
一个设备上批量执行多个脚本
@echo off
D:
cd D:\Desktop
title 正在执行第一个脚本
airtest run testdemo1.air
title 正在执行第二个脚本
airtest run testdemo2.air
title 正在执行第三个脚本
airtest run testdemo3.air
exit
一个脚本在多个设备上执行,其中设备名为连接手机名或者虚拟机远程连接地址
@echo off
D:
cd D:\Desktop
start "正在使用荣耀6手机运行脚本" airtest run testdemo.air --device Android:3LG4C17304008132
start "正在使用nova2手机脚本" airtest run testdemo.air --device Android:TPG5T18530014341
start "正在使用雷电模拟器跑脚本" airtest run testdemo.air --device Android://127.0.0.1:5037/emulator-5554
start "正在使用mumu模拟器跑脚本" airtest run testdemo.air --device Android://127.0.0.1:5037/127.0.0.1:7555
exit
资料来源参考引用项目官方公众号:AirtestProject
以上
Bobby
2020.11.18


















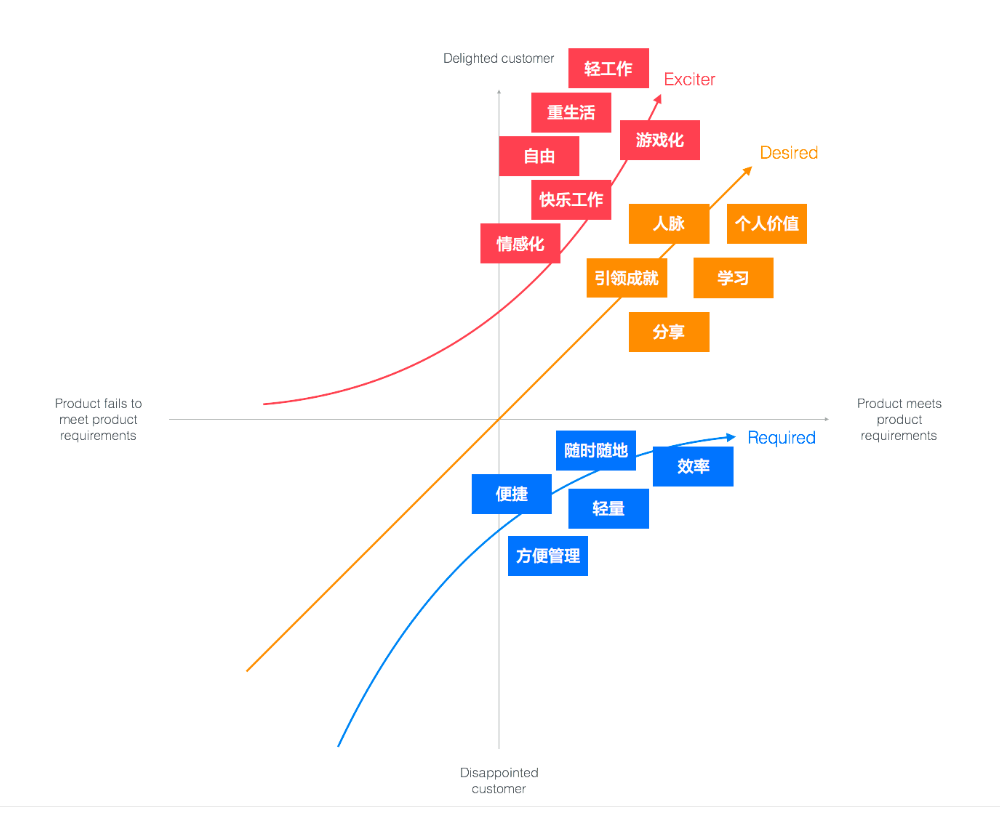 这很明显的展现了办公软件的几个层次,那么所对应的问题的解决层次也很明显,首先解决基本需求提高工作效率,其次是期望需求提高自我价值,然后就是魅力需求实现快乐工作。那么便针对不同的问题层次进行具体问题解决,完美飞蛇。
这很明显的展现了办公软件的几个层次,那么所对应的问题的解决层次也很明显,首先解决基本需求提高工作效率,其次是期望需求提高自我价值,然后就是魅力需求实现快乐工作。那么便针对不同的问题层次进行具体问题解决,完美飞蛇。